5 Characters, Glyphs, and Writing Modes
Table of contents
- 5.1 Is Your Journey Really Necessary?
- 5.2 Markup Constructs for Representation of Characters and Glyphs
- 5.3 Annotating Characters
- 5.4 Adding New Characters
- 5.5 How to Use Code Points from the Private Use Area
- 5.6 Writing Modes
- 5.7 Examples of Different Writing Modes
- 5.8 Text Rotation
- 5.9 Caveat
- 5.10 Formal Definition
Chapter vi. Languages and Character Sets introduced the fundamental notions of language identification and character representation in an encoded TEI document. In this chapter we discuss some additional issues relating to the way that written language is represented in a TEI document. In sections 5.1 Is Your Journey Really Necessary? and 5.2 Markup Constructs for Representation of Characters and Glyphs we introduce markup which may be used to represent and document non-standard characters, that is, written symbols for which no codepoint exists in Unicode. The same markup may be used to annotate existing characters according to their visual or other properties, and thus process them as distinct glyphs (see section 5.3 Annotating Characters), or to define new characters or glyphs (section 5.4 Adding New Characters). We also provide recommendations concerning the Unicode Private Use Area (5.5 How to Use Code Points from the Private Use Area. Finally, in section 5.6 Writing Modes we discuss ways of documenting the writing mode used in a source text, that is, the directionality of the script, the orientation of individual characters, and related questions.
TEI: Is Your Journey Really Necessary?⚓︎5.1 Is Your Journey Really Necessary?
Despite the availability of Unicode, text encoders still sometimes find that the published repertoire of available characters is inadequate to their needs. This is particularly the case when dealing with ancient languages, for which encoding standards do not yet exist, or where an encoder wishes to represent variant forms of a character or glyphs. The module defined by this chapter provides a mechanism to satisfy that need, while retaining compatibility with standards.
When encoders encounter some graphical unit in a document which is to be represented electronically, the first issue to be resolved should be ‘Is this really a different character?’ To determine whether a particular graphical unit is a character or not, see Terminology and Key Concepts.
If the unit is indeed determined to be a character, the next question should be ‘Has this character been encoded already?’ In order to determine whether a character has been encoded, encoders should follow the following steps:
Check the Unicode web site at https://www.unicode.org, in particular the page "Where is my Character?", and the associated character code charts. Alternatively, users can check the latest published version of The Unicode Standard (Unicode Consortium (2006)), though the web site is often more up to date than the printed version, and should be checked for preference.
The pictures (‘glyphs’) in the Unicode code charts are only meant to be representative, not definitive. If a specific form of an already encoded character is required for a project, refer to the guidelines contained below under Annotating Characters. Remember that your encoded document may be rendered on a system which has different fonts from yours: if the specific form of a character is important to you, then you should document it.
- Check the Proposed New Characters web page (https://unicode.org/alloc/Pipeline.html) to see whether the character is in line for approval.
- Ask on the Unicode email list (https://www.unicode.org/consortium/distlist.html) to see whether a proposal is pending, or to determine whether this character is considered eligible for addition to the Unicode Standard.
Since there are now over 130,000 characters in Unicode, chances are good that what you need is already there, but it might not be easy to find, since it might have a different name in Unicode. Editors working with East Asian writing systems should consult the Unihan Database. Look again, this time at other sites, preferably ones which also provide searches based on scripts and languages. For example https://www.chise.org (for CJK characters) or http://www.eki.ee/letter/ (for non-CJK characters) . Take care, however, that all the properties of what seems to be a relevant character are consistent with those of the character you are looking for. For example, if your character is definitely a digit, but the properties of the best match you can find for it say that it is a letter, you may have a character not yet defined in Unicode.
In general, it is advisable to avoid Unicode characters generally described as presentation
forms.26 However, if the character you are looking for is being used in a notation (rather
than as part of the orthography of a language) then it is quite acceptable to select
characters from the Mathematical Operators block, provided that they have the appropriate
properties (i.e. So: Symbol, Other; or Sm: Symbol, Math).
An encoded character may be precomposed or it may be formed from base characters and combining diacritical marks. Either will suffice for a character to be "found" as an encoded character. If there are several possible Unicode characters to choose amongst, it is good practice to consult other colleagues and practitioners to see whether a consensus has emerged in favour of one or other of them.
If, however, no suitable form of your character seems to exist, the next question will be: ‘Does the graphical unit in question represent a variant form of a known character, or does it represent a completely unencoded character?’ If the character is determined to be missing from the Unicode Standard, it would be helpful to submit the new character for inclusion (see https://unicode.org/pending/proposals.html). For assistance on writing or submitting a proposal, potential proposers can contact the UC Berkeley Script Encoding Initiative (http://linguistics.berkeley.edu/sei/).
These guidelines will help you proceed once you have identified a given graphical unit as either a variant or an unencoded character. Determining this will require knowledge of the contents of the document that you have. The first case will be called annotation of a character, while the second case will be called adding of a new character. How to handle graphical units that represent variants will be discussed below (5.3 Annotating Characters) while the problem of representing new characters will be dealt with in section 5.4 Adding New Characters.
While there is some overlap between these requirements, distinct specialized markup constructs have been created for each of these cases. These constructs are presented in section 5.2 Markup Constructs for Representation of Characters and Glyphs below.
TEI: Markup Constructs for Representation of Characters and Glyphs⚓︎5.2 Markup Constructs for Representation of Characters and Glyphs
An XML document can, in principle, contain any defined Unicode character. The standard
allows these characters to be represented either directly, using an appropriate encoding
(UTF-8 by default), or indirectly by means of a numeric character reference (NCR), such as Ä (A-umlaut). The encoder can also restrict the range of characters which are represented
directly in a document (or part of it) by adding a suitable encoding declaration.
For example, if a document begins with the declaration <?xml encoding="iso-8859-1"?> any Unicode characters which are not in the ISO-8859-1 character set must be represented
by NCRs.
The gaiji module defined by this chapter adds a further way of representing specific characters and glyphs in a document. (Gaiji is from Japanese 外字, meaning external characters.) This allows the encoder to distinguish characters and glyphs which Unicode regards as identical, to add new nonstandard characters or glyphs, and to represent Unicode characters not available in the document encoding by an alternative means.
The mechanism provided here consists functionally of two parts:
- an element g, which serves as a proxy for new characters or glyphs
- elements char and glyph, providing information about such characters or glyphs; these elements are stored in the charDecl element in the header.
When the gaiji module is included in a schema, the charDecl element is added to the model.encodingDescPart class, and the g element is added to the phrase class. These elements and their components are documented in the rest of this section.
The Unicode standard defines properties for all the characters it defines in the Unicode Character Database , knowledge of which is usually built into text processing systems. If the character represented by the g element does not exist in Unicode at all, its properties are not available. If the character represented is an existing Unicode character, but is not available in the document character set recognized by a given text processing system, it may also be convenient to have access to its properties in the same way. The char element makes it possible to store properties for use by such applications in a standard way.
The list of attributes (properties) for characters is modelled on those in the Unicode Character Database, which distinguishes normative and informative character properties. The Unicode Consortium also maintains a separate set of character properties specific to East Asian characters in the Unihan database which TEI fully supports. Lastly, non-Unicode properties may also be supplied. Since the list of properties will vary with different versions of the Unicode Standard, there may not be an exact correspondence between them and the list of properties defined in these Guidelines.
Usage examples for these elements are given below at 5.3 Annotating Characters and 5.4 Adding New Characters. The gaiji module itself is formally defined in section 5.10 Formal Definition below. It declares the following additional elements:
- charDecl (character declarations) provides information about nonstandard characters and glyphs.
- g (character or glyph) represents a glyph, or a non-standard character.
ref points to a description of the character or glyph intended.
The charDecl element is a member of the class model.encodingDescPart, and thus becomes available within encodingDesc when this module is included in a schema. The g element is the only member of the class model.gLike: this class is referenced as an alternative to plain text in almost every element which contains plain text, thus permitting the g element also to appear at such places when this module is included in a schema.
The following elements may appear within a charDecl element:
- desc (description) contains a short description of the purpose, function, or use of its parent element, or when the parent is a documentation element, describes or defines the object being documented.
- char (character) provides descriptive information about a character.
- glyph (character glyph) provides descriptive information about a character glyph.
The char and glyph elements have similar contents and are used in similar ways, but their functions are different. The char element is provided to define a character which is not available in the current document character set, for whatever reason, as stated above. The glyph element is used to annotate a character that has already been defined somewhere (either in the document character set, or through a char element) by providing a specific glyph that shows how a character appeared in the original document. This is necessary since Unicode code points refer not to a single, specific glyph shape of a character, but rather to a set of glyphs, any of which may be used to render the code point in question; in some cases they can differ considerably.
The glyph element is provided for cases where the encoder wants to specify a specific glyph (or family of glyphs) out of all possible glyphs. Unfortunately, due to the way Unicode has been defined, there are cases where several glyphs that logically belong together have been given separate code points, especially in the blocks defining East Asian characters. In such cases, glyph elements can also be used to express the view that these apparently distinct characters are to be regarded as instances of the same character (see further 5.3 Annotating Characters).
The Unicode Standard recommends naming conventions which should be followed strictly where the intention is to annotate an existing Unicode character, and which may also be used as a model when creating new names for characters or glyphs27:
Within both char and glyph, the following elements are available:
- gloss (gloss) identifies a phrase or word used to provide a gloss or definition for some other word or phrase.
- unicodeProp (unicode property) provides a Unicode property for a character (or glyph).
- unihanProp (unihan property) holds the name and value of a normative or informative Unihan character (or glyph) property as part of its attributes.
- localProp (locally defined property) provides a locally defined character (or glyph) property.
- desc (description) contains a short description of the purpose, function, or use of its parent element, or when the parent is a documentation element, describes or defines the object being documented.
- mapping (character mapping) contains one or more characters which are related to the parent character or glyph in some respect, as specified by the type attribute.
- figure (figure) groups elements representing or containing graphic information such as an illustration, formula, or figure.
- note (note) contains a note or annotation.
Four of these elements (gloss, desc, figure, and note) are defined by other TEI modules, and their usage here is no different from their usage elsewhere. The figure element, however, is used here only to link to an image of the character or glyph under discussion, or to contain a representation of it in SVG. The figure element may contain more than one graphic element, for example to provide images with different resolution, or in different formats, or may itself be repeated. As elsewhere, the mimeType attribute of graphic should be used to specify the format of the image.
exact for exact equivalences, uppercase for uppercase equivalences, lowercase for lowercase equivalences, standard for standardized forms, and simplified for simplified characters, etc., as in the following example:
<char xml:id="aenl">
<localProp name="name"
value="LATIN LETTER ENLARGED SMALL A"/>
<localProp name="entity" value="aenl"/>
<mapping type="standard">a</mapping>
</char>
</charDecl>
<glyph xml:id="z103">
<localProp name="name"
value="LATIN LETTER Z WITH TWO STROKES"/>
<mapping type="standard">Z</mapping>
<mapping type="PUA">U+E304</mapping>
</glyph>
</charDecl>
A more precise documentation of the properties of any character or glyph may be supplied using one of the three ‘property’ elements: localProp, unicodeProp, or unihanProp; these are described in the next section.
TEI: Character Properties⚓︎5.2.1 Character Properties
The Unicode Standard documents ‘ideal’ characters, defined by reference to a number
of properties (or attribute-value pairs) which they are said to possess. For example, a lowercase
letter is said to have the value Ll for the property General_Category. The Standard distinguishes between normative properties (i.e. properties which form part of the definition of a given character),
and informative or additional properties which are not normative. It also allows for the addition of new properties,
and (in some circumstances) alteration of the values currently assigned to certain
properties. When making such modifications, great care should be taken not to override
standard informative properties for characters which already exist in the Unicode
Standard, as documented in Freytag (2006).
The unicodeProp, unihanProp, and localProp elements allow a TEI encoder to record information about a character or glyph:
- unicodeProp (unicode property) provides a Unicode property for a character (or glyph).
name specifies the normalized name of a Unicode property. value specifies the value of a named Unicode property. - unihanProp (unihan property) holds the name and value of a normative or informative Unihan character
(or glyph) property as part of its attributes.
name specifies the normalized name of a unicode han database (Unihan) property. value specifies the value of a named Unihan property - localProp (locally defined property) provides a locally defined character (or glyph) property.
name [att.gaijiProp] provides the name of the character or glyph property being defined. value [att.gaijiProp] provides the value of the character or glyph property being defined.
Where the information concerned relates to a property which has already been identified in the Unicode Standard, use of the appropriate Unicode property name with unicodeProp is strongly encouraged. The use of available Unihan property names with unihanProp is similarly encouraged. Validation rules for property names according to Unicode conventions are incorporated into the TEI schemas. Where neither of these standards suffices use localProp.
- att.gaijiProp provides attributes for defining the properties of non-standard characters or glyphs.
name provides the name of the character or glyph property being defined. value provides the value of the character or glyph property being defined.
value="false"/>
For convenience, we list here some of the normative character properties and their values. For full information, refer to chapter 4 of The Unicode Standard, or the online documentation of the Unicode Character Database.
- General_Category
- The general category (described in the Unicode Standard chapter 4 section 5) is an
assignment to some major classes and subclasses of characters. Suggested values for
this property are listed here:
LuLetter, uppercase LlLetter, lowercase LtLetter, titlecase LmLetter, modifier LoLetter, other MnMark, nonspacing McMark, spacing combining MeMark, enclosing NdNumber, decimal digit NlNumber, letter NoNumber, other PcPunctuation, connector PdPunctuation, dash PsPunctuation, open PePunctuation, close PiPunctuation, initial quote PfPunctuation, final quote PoPunctuation, other SmSymbol, math ScSymbol, currency SkSymbol, modifier SoSymbol, other ZsSeparator, space ZlSeparator, line ZpSeparator, paragraph CcOther, control CfOther, format CsOther, surrogate CoOther, private use CnOther, not assigned - Bidi_Class
- This property applies to all Unicode characters. It governs the application of the
algorithm for bi-directional behaviour, as further specified in Unicode Annex 9, The Bidirectional Algorithm. The following 21 different values are currently defined for this property:
LLeft-to-Right RRight-to-Left ALRight-to-Left Arabic ENEuropean Number ESEuropean Number Separator ETEuropean Number Terminator ANArabic Number CSCommon Number Separator NSMNonspacing Mark BNBoundary Neutral BParagraph Separator SSegment Separator WSWhitespace ONOther Neutrals LRELeft-to-Right Embedding LROLeft-to-Right Override RLERight-to-Left Embedding RLORight-to-Left Override PDFPop Directional Format LRILeft-to-Right Isolate RLIRight-to-Left Isolate FSIFirst Strong Isolate PDIPop Directional Isolate - Canonical_Combining_Class
- This property exists for characters that are not used independently, but in combination
with other characters, for example the strokes making up CJK (Chinese, Japanese, and
Korean) characters. It records a class for these characters, which is used to determine
how they interact typographically. The following values are defined in the Unicode
Standard: (see Unicode Character Database: Canonical Combining Class Values); these were taken from version 12.1:
0Spacing, split, enclosing, reordrant, and Tibetan subjoined 1Overlays and interior 7Nuktas 8Hiragana/Katakana voicing marks 9Viramas 10Start of fixed position classes 199End of fixed position classes 200Below left attached 202Below attached 204Below right attached 208Left attached (reordrant around single base character) 210Right attached 212Above left attached 214Above attached 216Above right attached 218Below left 220Below 222Below right 224Left (reordrant around single base character) 226Right 228Above left 230Above 232Above right 233Double below 234Double above 240Below (iota subscript) - Decomposition_Mapping
- This property is defined for characters, which may be decomposed, for example to a
canonical form plus a typographic variation of some kind. For such characters the
Unicode standard specifies both a decomposition type and a decomposition mapping (i.e.
another Unicode character to which this one may be mapped in the way specified by
the decomposition type). The following types of mapping are defined in the Unicode
Standard:
fontA font variant (e.g. a blackletter form) noBreakA no-break version of a space or hyphen initialAn initial presentation form (Arabic) medialA medial presentation form (Arabic) finalA final presentation form (Arabic) isolatedAn isolated presentation form (Arabic) circleAn encircled form superA superscript form subA subscript form verticalA vertical layout presentation form wideA wide (or zenkaku) compatibility character narrowA narrow (or hankaku) compatibility character smallA small variant form (CNS compatibility) squareA CJK squared font variant fractionA vulgar fraction form compatOtherwise-unspecified compatibility character - Numeric_Value
- This property applies for any character which expresses any kind of numeric value. Its value is the intended value in decimal notation.
- mirrored
- The mirrored character property is used to properly render characters such as U+0028,
OPENING PARENTHESISindependent of the text direction: it has the valueY(character is mirrored) orN(code is not mirrored).
The Unicode Standard also defines a set of informative (but non-normative) properties for Unicode characters. If encoders wish to provide such properties, they should be included using the Unicode name. If a Unicode name exists for a given character this should always be used, however encoders may also supply locally defined names. To tag a Unicode name, use <unicodeProp name="Name"> (or <unihanProp name="Name">). For names specified elsewhere or specified locally use localProp.
TEI: Annotating Characters⚓︎5.3 Annotating Characters
Annotation of a character becomes necessary when it is desired to distinguish it on the basis of certain aspects (typically, its graphical appearance) only. In a manuscript, for example, where distinctly different forms of the letter r can be recognized, it might be useful to distinguish them for analytic purposes, quite distinct from the need to provide an accurate representation of the page. A digital facsimile, particularly one linked to a transcribed and encoded version of the text, will always provide a superior visual representation (for information on how to link a digital facsimile to a transcribed text see 12.1 Digital Facsimiles), but cannot be used to support arguments based on the distribution of such different forms. Character annotation as described here provides a solution to this problem.28
<glyph xml:id="r1">
<localProp name="name"
value="LATIN SMALL LETTER R WITH ONE FUNNY STROKE"/>
<localProp name="entity" value="r1"/>
<figure>
<graphic url="r1img.png"/>
</figure>
</glyph>
<glyph xml:id="r2">
<localProp name="name"
value="LATIN SMALL LETTER R WITH TWO FUNNY STROKES"/>
<localProp name="entity" value="r2"/>
<figure>
<graphic url="r2img.png"/>
</figure>
</glyph>
</charDecl>
manusc<g ref="#r2">r</g>ipt are sometimes
written in a funny way.</p>
<!-- in the charDecl -->
<glyph xml:id="Filig">
<localProp name="Name"
value="LATIN UPPER F AND LATIN LOWER I LIGATURE"/>
<figure>
<graphic url="Filig.png"/>
</figure>
</glyph>
<g ref="#per">per</g>
</abbr> ardua</p>
<!-- in the charDecl -->
<glyph xml:id="per">
<localProp name="Name"
value="LATIN ABBREVIATION PER"/>
<figure>
<graphic url="per.png"/>
</figure>
</glyph>
Fi ligature; the encoder may however prefer not to use it in order to simplify other
text processing operations, such as indexing).With this markup in place, it will be possible to write programs to analyze the distribution of the different letters r as well as produce more ‘faithful’ renderings of the original. It will also be possible to produce normalized versions by simply ignoring the annotation pointed to by the element g.
For brevity of encoding, it may be preferred to predefine internal entities such as the following:
<!ENTITY r1 '<g ref="#r1">r</g>' > <!ENTITY r2 '<g ref="#r2">r</g>' >⚓
which would enable the same material to be encoded as follows:
<p>Wo&r1;ds in this manusc&r2;ipt are sometimes written in a funny way.</p> ⚓
The same technique may be used to represent particular abbreviation marks as well
as to represent other characters or glyphs. For example, if we believe that the r-with-one-funny-stroke
is being used as an abbreviation for receipt, this might be represented as follows:
<abbr>&r1;</abbr>⚓
Note however that this technique employs markup objects to provide a link between a character in the document and some annotation on that character. Therefore, it cannot be used in places where such markup constructs are not allowed, notably in attribute values.
<glyph xml:id="u8aaa">
<mapping type="Unicode">說</mapping>
<mapping type="standard">説</mapping>
</glyph>
</charDecl>
<char xml:id="newchar1">
<!-- more properties here -->
</char>
<glyph xml:id="varofnewchar1">
<!-- more properties here -->
<mapping type="standard">
<g ref="#newchar1"/>
</mapping>
</glyph>
</charDecl>
TEI: Adding New Characters⚓︎5.4 Adding New Characters
The creation of additional characters for use in text encoding is quite similar to the annotation of existing characters. The same element g is used to provide a link from the character instance in the text to a character definition provided within the charDecl element. This character definition takes the form of a char element. The element g itself will usually be empty, but could contain a code point from the Private Use Area (PUA) of the Unicode Standard, which is an area set aside for the very purpose of privately adding new characters to a document. Recommendations on how to use such PUA characters are given in the following section.
&ydotacute;, which when the transcription is processed can then be expanded in one of three ways,
depending on the mapping in force. The entity reference might be translated into the
sequence of corresponding Unicode code points or into some locally-defined PUA character
(say ) for local processing only. Both these options have disadvantages; the former loses
the fact that the sequence of composed characters is regarded as a single object;
the second is not reliably portable. Therefore, the recommended representation is
to use the g element defined by the module defined in this chapter:
<localProp name="Name"
value="LATIN SMALL LETTER Y WITH DOT ABOVE AND ACUTE"/>
<localProp name="entity" value="ydotacute"/>
<mapping type="composed">ẏ́</mapping>
<mapping type="PUA">U+E0A4</mapping>
</char>
&ydotacute; above. For these cases Unicode provides dedicated symbols to capture the composition
in Ideographic Description Sequences (IDS). Encoders are strongly encouraged to provide
IDS for each variant ideograph in the header component of the gaiji module to faciliated
greater human and machine readability of rare or unencoded characters, as in the following
example:
<!-- more properties here -->
<mapping type="IDS">⿻人為</mapping>
<mapping type="standard">偽</mapping>
</glyph>
人) the circled variant might conveniently be represented as
<unicodeProp name="Decomposition_Mapping"
value="cicle"/>
<localProp name="Name"
value="CIRCLED IDEOGRAPH 36"/>
<localProp name="daikanwa" value="36"/>
<mapping type="standard"> 人
</mapping>
<mapping type="PUA"> 
</mapping>
</char>
In this example, the ‘circled ideograph’ character has been defined with two mappings,
and with two properties. The two properties are the Unicode-defined character-decomposition
which specifies that this is a circled character, using the appropriate terminology
(see 5.2.1 Character Properties above) and a locally defined property known as ‘daikanwa’. The two mappings indicate
firstly that the standard form of this character is the character 人, and secondly that the character used to represent this character locally is the
PUA character . For convenience of local processing this PUA character may in fact appear as content
of the g element. In general, however, the g element will be empty.
TEI: How to Use Code Points from the Private Use Area⚓︎5.5 How to Use Code Points from the Private Use Area
The developers of the Unicode Standard have set aside an area of the codespace for the private use of software vendors, user groups, or individuals. As of this writing (Unicode 12.1), there are around 137,000 code points available in this area, which should be enough for most needs. No code point assignments will be made to this area by standard bodies and only some very basic default properties have been assigned (which may be overridden where necessary by the mechanism outlined in this chapter). Therefore, unlike all other code points defined by the Unicode Standard, PUA code points should not be used directly in documents intended for blind interchange.
In the two previous examples, we mentioned that the variant characters concerned might well be assigned specific code points from the PUA. This might, for example, facilitate the use of a particular font which displays the desired character at this code point in the local processing environment. Since however this assignment would be valid only on the local site, documents containing such code points are unsuitable for blind interchange. During the process of preparing such documents for interchange, any PUA code points should be replaced by an appropriate use of the g element, such as <g ref="#xxxx">, thus associating the character required with the documentation of it provided by the referenced char element. The PUA character used during the preparation of the document might be recorded in the char element, as shown in the example in 5.4 Adding New Characters, or retained as content of the g element. However, since there is no requirement that the same PUA character be used to represent it at the receiving site, and since it may well be the case that this other site has already made an assignment of some other character to the original PUA code point, it is best practice to remove the locally-defined PUA character. It is to be expected that a further translation into the local processing environment at the receiving site will be necessary to handle such characters, during which variant letters can be converted to hitherto unused code points on the basis of the information provided in the char element.
This mechanism is rather weak in cases where DOM trees or parsed XML fragments are exchanged, which may increasingly be the case. The best an application can do here is to treat any occurrence of a PUA character only in the context of the local document and use the properties provided through the char element as a handle to the character in other contexts.
In the fullness of time, a character may become standardized, and thus assigned a specific code point outside the PUA. Documents which have been encoded using the mechanism must at the least ensure that this changed code point is recorded within the relevant char element; it will however normally be simpler to remove the char element and replace all occurrences of g elements which reference it by occurrences of the newly coded character.
TEI: Writing Modes⚓︎5.6 Writing Modes
The scripts used for writing human languages vary not only in the glyphs they use, but also in the way (or ways) that those glyphs are arranged on the writing surface. For the majority of modern languages, writing is arranged as a series of lines which are to be read from top to bottom. Within each line, individual characters are frequently presented from left to right (English, Russian, Greek), but there are also several widely-used scripts which run right-to-left (Arabic, Hebrew). Writing in which the lines of glyphs are presented vertically and read from right to left is also often encountered, notably in East Asian scripts (Sinitic characters, Japanese Kana, Korean Hangul, Vietnamese chữ nôm). In many cases, a language normally uses the same writing mode (we use this term to refer to the orientation of individual glyphs within a line and the order in which glyphs and lines should be read), but there are exceptions in which the same language may appear in different modes, for example either vertically or horizontally. Many East Asian scripts were traditionally written from top to bottom within the line, with their lines sequenced from right to left. Although modern Japanese, Chinese, and Korean are often written horizontally, the traditional vertical writing mode is still widely used. There are also comparatively rare cases of ancient scripts written with lines running left to right, each line being read top to bottom (Ancient Uighur, classical Mongolian and Manchu), or scripts such as Ogham where the writing direction may start from the bottom left and run around the edge of an inscribed object.
When different languages are combined, it is possible that different writing modes will be needed: for example, in Hebrew text, running right to left, sequences of Latin digits still run left to right. When different writing modes are available for the same language, it may be that different glyphs will be preferred when the script is used in different modes. For example, when Japanese is written horizontally, the Unicode character U+3001, the ‘ideographic comma’, is used in preference to Unicode character U+FE11, the vertical mode comma. This ensures that the comma appears in the correct position relative to the surrounding glyphs. Even for scripts which are usually written in exactly the same way, different writing modes may be encountered in particular contexts; for example when a language using Roman script is embedded within vertically-organized Chinese text, it may sometimes be displayed vertically and sometimes horizontally. The writing mode may also vary in response to layout constraints such as those imposed by a complex table, where column or row labels may be written vertically or diagonally to make the most effective use of available space, just as it may vary in response to the size and shape of the carrier in the case of a monumental inscription.
For many, perhaps most, TEI documents there may be no need to encode the writing mode explicitly, even in so-called "mixed mode" texts containing passages written in languages which use different writing modes. Modern printed texts in most European languages, for instance, may be expected to use left-to-right/top-to-bottom directionality; while Arabic or Hebrew texts are expected to run right-to-left/top-to-bottom. In a TEI document, language and script are explicitly stated in the markup using the attribute xml:lang; this indication will usually imply a particular default writing mode. Even where this attribute is not used, passages in different scripts will use different Unicode characters, and will thus imply a particular default writing mode.
The Arabic term قلم رصاص means "pencil".⚓A correct TEI encoding might read as follows:
<term xml:lang="ar">قلم رصاص</term> means "pencil".</s>
The Unicode Bidirectional Algorithm (Unicode Consortium, 2017) defines a number of rules enabling software to render sequences of characters which have differing directionality properties in a predictable and reliable way, using only those properties. 29. It should be remembered however that individual sequences of characters are always stored in a file in the order in which they should be read, irrespective of the order in which the characters making up a sequence should be displayed or rendered. For example, in a RTL language such as Hebrew, the first character in a file will be that which is displayed at the rightmost end of the first line of text.
An encoder wishing to document or to control the order in which sequences of characters
in a TEI document are displayed will usually do so by segmenting the text into sequences
presented in the desired order and specifying an appropriate language code for each.
In situations where this approach may result in ambiguity or lack of precision, or
if the encoder wishes to record directional information explicitly in their encoding,
we recommend using the global @style attribute to supply detail about the writing
mode applicable to the content of any element. The style attribute (discussed in 1.3.1.1.3 Rendition Indicators) permits use of any formatting language; for these purposes however, we recommend
use of CSS, which includes a Writing Modes module 30 which permits direct specification of a number of useful properties associated with
writing modes, notably direction (ltr or rtl); writing-mode (horizontal-tb, vertical-rl, or vertical-lr); and text-orientation (mixed, upright, sideways ...) as well as properties affecting the behaviour of the unicode-bidi (bidirectional)
algorithm. We discuss and exemplify how these properties may be used below.
The global TEI style attribute applies to the element on which it is specified (and in most cases, its descendants). Rather than specify it on every element, it will often be more efficient to express sets of commonly-used styling rules as rendition elements in the teiHeader and then point to them using the global rendition attribute, as further discussed in 2.3.4.1 Rendition. Although the CSS specifications are mainly used to provide instructions for software when rendering a digital text, they also provide a useful means of describing the visual properties of a pre-existing document in a formal and standardized way.
The next section presents some examples of how CSS can be used to describe a variety of writing modes. A full description of the appearance of a document will probably include many other properties of course.
TEI: Examples of Different Writing Modes⚓︎5.7 Examples of Different Writing Modes
The CSS recommendations provides several properties which can be used to encode aspects of the "writing mode". The most useful of these is the property "writing-mode" which may be used to specify a reading-order for both characters within a single line and lines within a single block of text. The property "text-orientation" may also used to indicate the orientation of individual characters with respect to the line, and the property "direction" to determine the reading order of characters within a line only. We give some examples of each below.
TEI: Vertical Writing Modes⚓︎5.7.1 Vertical Writing Modes
The writing-mode property is particularly useful for languages which can be written in different writing
modes, such as Chinese and Japanese. Its possible values include horizontal-tb, vertical-rl and vertical-lr. Each value has two components: ‘horizontal’ or ‘vertical’ specifies the inline writing
direction, while the second component specifies the direction in which lines in a
block, and blocks in a sequence are arranged: from top to bottom (as in most European
languages, in which lines and paragraphs are arranged from top to bottom on a page),
from right to left (as in the case of Japanese written vertically), or left-to-right
(as in the case of Mongolian).
The following example shows three versions of the same poem: first in Japanese, written top to bottom; next in romaji (Japanese in Latin script); and finally in an English translation.

We might encode this as follows:
<lg xml:lang="ja"
style="writing-mode: vertical-rl">
<l>古池や</l>
<l>蛙</l>
<l>飛び込む</l>
<l>水の音</l>
</lg>
<lg xml:lang="ja-Latn"
style="writing-mode: horizontal-tb">
<l>furu ike ya</l>
<l>kawazu tobikomu</l>
<l>mizu no oto</l>
</lg>
<lg xml:lang="en">
<l>Old pond,</l>
<l>and a frog dives in—</l>
<l>"Splash"!</l>
</lg>
</div>
For the sake of simplicity, we have not attempted to capture in this encoding such
aspects as the indenting of lines in the first Japanese version, or the central alignment
of the other two versions, nor any other renditional features such as font weight
or size etc. The Japanese transcription has writing-mode: vertical-rl, which is required because Japanese may be written either in this mode or horizontally.
The transcription in romaji uses the attribute xml:lang to supply a value of ja-Latn, indicating Japanese written in Latin script. Its style attribute specifies a horizontal writing mode; this may seem superfluous, but vertically-written
romaji is not unknown.
TEI: Vertical Text with Embedded Horizontal Text⚓︎5.7.2 Vertical Text with Embedded Horizontal Text
When Japanese is written vertically, the glyph orientation remains the same as when it is written horizontally. In other words, glyphs are not rotated (although as noted above some different glyphs may be used for some characters, in particular for punctuation which needs to be positioned differently in vertical and in horizontal text). However, it is very common for languages written vertically to have embedded runs of text from languages which are normally written horizontally. This raises the issue of the orientation of the glyphs from the horizontal language. Are they written upright, as they would normally appear in horizontal text runs, or are they rotated? Consider this fragment from a Japanese article about the Indonesian language, which takes the form of a glossary list:

The text-orientation property allows us to indicate whether or not glyphs are rotated.
In the following example, we have indicated that the list uses a vertical-rl writing mode, but that the orientation of individual glyphs may vary:
style="writing-mode: vertical-rl; text-orientation: mixed">
<label xml:lang="id">hampir</label>
<item>「近い、ほとんど」</item>
<label xml:lang="id">baru</label>
<item>「新しい、ばかい」</item>
<!-- ... -->
</list>
The rule text-orientation: mixed specifies that ‘characters from horizontal-only scripts are set sideways, i.e. 90° clockwise from
their standard orientation in horizontal text. Characters from vertical scripts are
set with their intrinsic orientation’ (fantasai 2014). Since the default value for text-orientation is mixed, this rule is not strictly required. However, if the Indonesian glyphs (which are
roman characters) had been set vertically, like this:

then an encoding like the following could be used to make this explicit:
style="writing-mode: vertical-rl; text-orientation: upright">
<label xml:lang="id">hampir</label>
<item>「近い、ほとんど」</item>
<label xml:lang="id">baru</label>
<item>「新しい、ばかい」</item>
<!-- ... -->
</list>
The rule text-orientation: upright specifies that ‘characters from horizontal-only scripts are rendered upright, i.e. in their standard
horizontal orientation. Characters from vertical scripts are set with their intrinsic
orientation and shaped normally’ (fantasai 2014).
TEI: Vertical Orientation in Horizontal Scripts⚓︎5.7.3 Vertical Orientation in Horizontal Scripts
It is not unusual to see text from horizontal languages written vertically even where no vertically-written script is involved. This example is a fragment from a table of information about agricultural development on Vancouver Island, written in 1855:
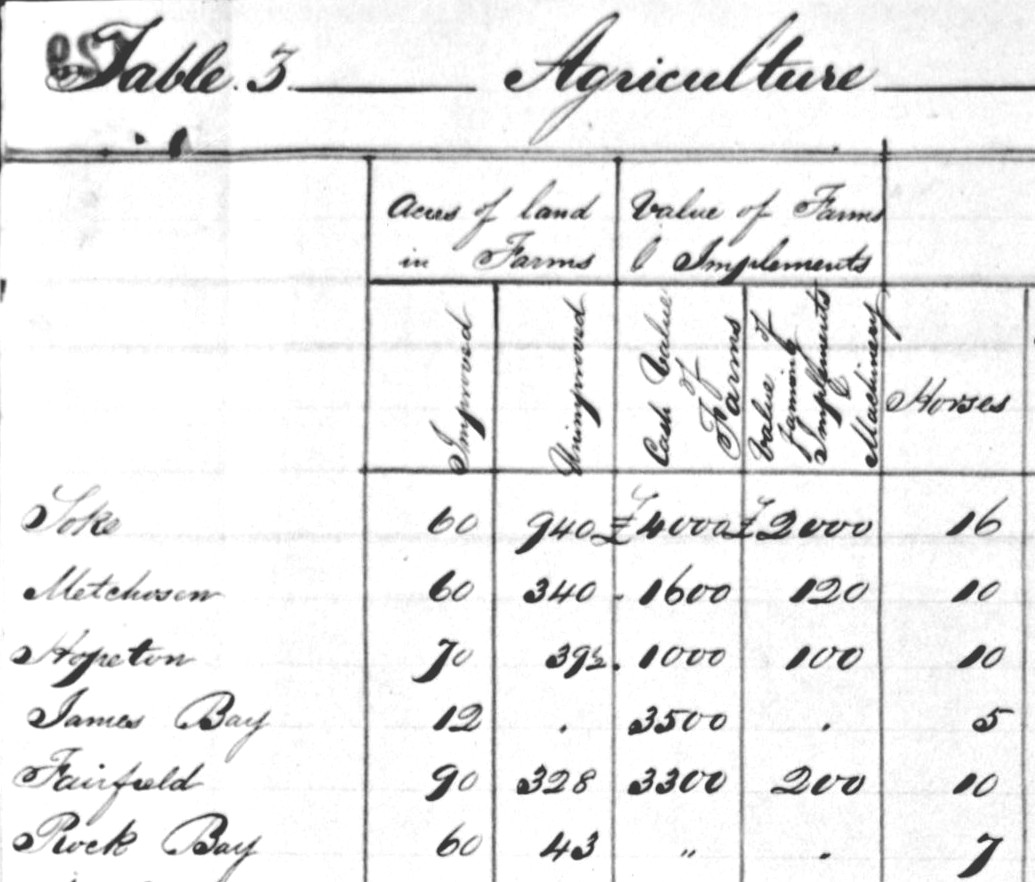
Four of the subheading cells in this fragment contain English text written vertically,
bottom-to-top, to conserve space on the page. To describe this sort of phenomenon,
we can use the text-orientation property again:
text-orientation: mixed | upright | sideways-right | sideways-left | sideways | use-glyph-orientation
For full details on this property, we refer the reader to the CSS Writing Modes specification. For the present example, we will make use only of the ‘sideways-left’ value, which ‘causes text to be set as if in a horizontal layout, but rotated 90° counter-clockwise.’ We might encode the third of the four cells containing vertical text like this:
<lb/>Cash Value
<lb/>of
<lb/>Farms
</cell>
The writing-mode property captures the fact that the script is written vertically, and its lines are
to be read from left to right (so the line containing ‘of’ is to the right of that containing ‘Cash value’), while the text-orientation value encodes the orientation (rotated 90° counter-clockwise). We might also add
text-align: center to the style, to express the fact that the text is centrally-aligned.
TEI: Bottom-to-top Writing⚓︎5.7.4 Bottom-to-top Writing
Of the rather small number of scripts which appear to be written bottom-to-top, perhaps
the best-known is Ogham, an alphabet used mainly to write Archaic Irish. Ogham is
typically found inscribed along the edge of a standing stone, starting at its base.
The CSS Writing Modes specification does not explicitly distinguish between vertical
scripts which are written top-to-bottom and those which are written bottom-to-top.
Instead, such bottom-to-top scripts are best treated as left-to-right horizontal scripts,
oriented vertically because of the constraints of the medium on which they are inscribed.
Such scripts are analogous to the vertical English text-runs in the table cells in
the example above, and can be handled in exactly the same manner (writing-mode: vertical-lr; text-orientation: sideways-left). In cases where writing follows a curved path (such as Ogham running around the
edge of a stone), a meticulous encoder might resort to the use of SVG to describe
the path, rather than treating the phenomenon as a writing mode.
TEI: Mixed Horizontal Directionality⚓︎5.7.5 Mixed Horizontal Directionality
Returning to our previous simple example
The Arabic term قلم رصاص means "pencil".⚓
we could use the direction property to make directionality explicit:
direction: ltr | rtl
<term xml:lang="ar"
style="direction: rtl; unicode-bidi: embed">قلم رصاص</term> means "pencil".</s>
The use of the direction property to record the observed directionality of the text is unambiguous, even though
it is (as we noted above) superfluous. The use of the unicode-bidi property here may require some explanation. By default this property has the value
‘normal’, the effect of which in this context would be to ignore any value supplied
for the direction property. The CSS Writing Modes specification stipulates that the
direction property ‘has no effect on bidi reordering when specified on inline boxes whose unicode-bidi property’s value is ‘normal’, because the element does not open an additional level
of embedding with respect to the bidirectional algorithm.’
Mixed horizontal directionality is very common in languages such as Arabic and Hebrew, particularly when numbers (which are always given LTR) or phrases from LTR languages are embedded. It is not impossible, though quite unusual, for ambiguities to arise in such situations, which may give rise to the parts of a document being displayed in unexpected ways that do not correspond to the natural reading order. A more detailed discussion of this issue from an HTML perspective is provided by a W3C Internationalization Working Group report Inline markup and bidirectional text in HTML.
TEI: Summary⚓︎5.7.6 Summary
For most texts, information about text directionality need not be explicitly encoded in a TEI text, either because it follows unambiguously from xml:lang values, or because it can be expected to be handled unequivocally by the Unicode Bidi Algorithm. Where it is considered important to encode such information, properties and values taken from the CSS Writing Modes module may be used by means of the global TEI style attribute (or using the TEI rendition element, linked with the rendition attribute). Most phenomena can be well described in this way; of those which cannot, other approaches based on the CSS Transforms module are presented in the next section.
TEI: Text Rotation⚓︎5.8 Text Rotation
In what follows, we examine a range of textual phenomena which in some ways appear very similar to those examined above, and even overlap with them. We can categorize these as text transformation features, and suggest some strategies for encoding them based on the properties detailed in the CSS Transforms (Fraser et al 2013) specification. This CSS module provides a complex array of properties, values and functions which can be used to rotate, skew, translate and otherwise transform textual and graphical objects. We can borrow this vocabulary in order to describe textual phenomena in a precise manner.
We begin with a simple example of a rotational transform:

Here a block of text has been rotated around its z-axis. This is clearly not a ‘writing
mode’; the writing mode for this text is horizontal, left to right. Furthermore, even
if we wished to treat this as a writing mode, we could not do so, because there is
no way to use writing modes properties to describe an text orientation which is angled
at 45 degrees; no human languages are consistently written in this orientation. It
is more appropriate to treat this as a rotational transformation. We can do this using
two properties: transform and transform-origin. (Both of these properties have quite complex value sets, and we will not look at
all of them here. See the specification for full details.)
The transform property takes as its value one or more of the transform functions, one of which
is the function rotateZ():
Any rotation must take place clockwise around an axis positioned relative to the element
being rotated, and the transform-origin property can be used to specify the pivot point. By default, the value of transform-origin is ‘50% 50%’, the point at the centre of the element, but these values can be changed
to reflect rotation around a different origin point. (The TEI zone element also bears an attribute rotate which can specify rotation in degrees around the z-axis, but it is not available
for any other element.)
A block of text may also be rotated about either of its other axes. For example, this shows rotation around the Y (vertical) axis:

These are obviously trivial examples, but similar features do appear in historical
texts. George Herbert's The Temple includes two stanzas headed Easter Wings
which are both normally printed in a rotated form so that they represent a pair of
wings:

This could be encoded thus:
<l>My tender age in ſorrow did beginne:</l>
<l>And ſtill with ſickneſſes and ſhame</l>
<!-- ... -->
</lg>
We might also argue that this is in fact a vertical writing mode by supplying writing-mode: vertical-rl; text-orientation: sideways-right as the value for the style attribute in the preceding example.
Rotation is also useful as a method of handling a true writing mode which is not covered by the CSS Writing Modes: boustrophedon. This is a writing mode common in inscriptions in Latin, Greek and other languages, in which alternate lines run from left to right and from right to left31. Right-to-left lines in boustrophedon have another unexpected feature: their glyphs are reversed, so that these lines appear as ‘mirror writing’, as in the following ancient Greek inscription:

This might be transcribed as follows (ignoring word boundaries for the moment):
<lb/>ΗΕΡΜΟΝΤΙΝA
<lb/>
<seg style="rotateY(180deg)">ΚΑΘΕΟΝΠΟΤΘΕΜ</seg>
<lb/>ΕΝΟΣΥΕΝΕΑϜ
<lb/>
<seg style="rotateY(180deg)">ΟΙΥΕΝΟΙΤΙΕΚΚ</seg>
<lb/>ΡΕΤΑΙΑΣΟΝΑ
<lb/>
<seg style="rotateY(180deg)">ΣΙΜΟΣΟΤΤΑΙΕ</seg>
<lb/>ΑΣΣΑΙ
</ab>
The 180-degree rotation around the Y (vertical) axis here describes what is happening in the RTL lines in boustrophedon; the order of glyphs is reversed, and so is their individual orientation (in fact, we see them ‘from the back’, as it were). seg elements have been used here because these are clearly not ‘lines’ in the sense of poetic lines; the text is continuous prose, and the division into separate lines is incidental.
There are obviously some unsatisfactory aspects of this manner of encoding boustrophedon. In the inscription above, some words are split across two lines, so if we wished to tag both words and the right-to-left phenomena, one hierarchy would have to be privileged over the other. By using a transform function rather than a writing mode property, we are apparently suggesting that boustrophedon is not in fact a writing mode, whereas it clearly is. But the CSS Writing Modes specification does not provide support for boustrophedon, because it is a rather obscure historical phenomenon; using a rotational transform is one practical alternative.
TEI: Caveat⚓︎5.9 Caveat
As with other parts of the CSS specification, the intended effect of CSS Transforms properties and values is defined with reference to a specific Visual formatting model; the language is designed to describe how an HTML document should be formatted. This is not, of course, the case for the TEI, which lacks any explicit processing or formatting model, and attempts to define objects as far as possible without consideration of their visual appearance. As long as the properties and values from the CSS Transforms module are used as a convenient, well-specified descriptive language to capture features of a text, without any expectation of using them directly and reliably for rendering, this is not particularly problematic. CSS provides a useful and well-defined vocabulary to describe many aspects of the appearance of source texts, benefitting particularly from the clarity of definition provided by the specification. However, if there is any expectation of using this information to render a text in a predictable and accurate way, it will be essential to provide enough styling information throughout the document hierarchy to resolve all ambiguities with regard to size, positioning, block status, etc. before any element undergoes a transform operation.
TEI: Formal Definition⚓︎5.10 Formal Definition
The gaiji module described in this chapter makes available the following components:
- Module gaiji: Character and glyph documentation
-
- Elements defined: char charDecl g glyph localProp mapping unicodeProp unihanProp
- Classes defined: att.gaijiProp
The selection and combination of modules to form a TEI schema is described in 1.2 Defining a TEI Schema.
U+4E00’, where U+4E00 is simply the Unicode code point value of the character in question. In cases where
no Unicode code point exists, there is little hope of finding a name that helps to
identify the character. Names should therefore be constructed in a way meaningful
to local practice, for example by using a reference number from a well-known character
dictionary or a project-specific serial number.